Want to block a sub-domain from robots.txt so that search engines don’t crawl it?
Today I’ll show you how to use robots.txt to block sub-domain.
There is a simple way to remove the entire sub-domain or selected directories on the subdomain from search results.
I have also used these techniques to disallow multilevel subdomains. But for multilevel subdomains, the trick is a bit different!
So, whether you want to disallow one of your entire subdomains or a particular folder, you can follow this guide.
What Is a robots.txt File?
A robots.txt file is a unique text file within your website’s root directory that instructs search engine crawlers on which pages of the website they should crawl and which pages they should not crawl.
These crawl instructions are defined by “allowing” or “disallowing” specific web crawling behavior. It is used to avoid overloading your website with requests.
And, making sure only relevant pages are indexed & confidential pages (like pages that have login credentials of the website) are not indexed in SERPs
Now let’s see…
How to Use robots.txt to Block Search Engine Crawlers from Accessing the Subdomain
If you don’t want bots to index certain subdomains, you can block them using the robots.txt file.
Step I: Open Notepad in your system & add the following code:
User-agent: *
Disallow: /Step II: Save the file on your system with the name “robots.txt”.
Step III: Now upload the saved robots.txt file to the root directory of each sub-domain you want to protect from search engine crawlers.
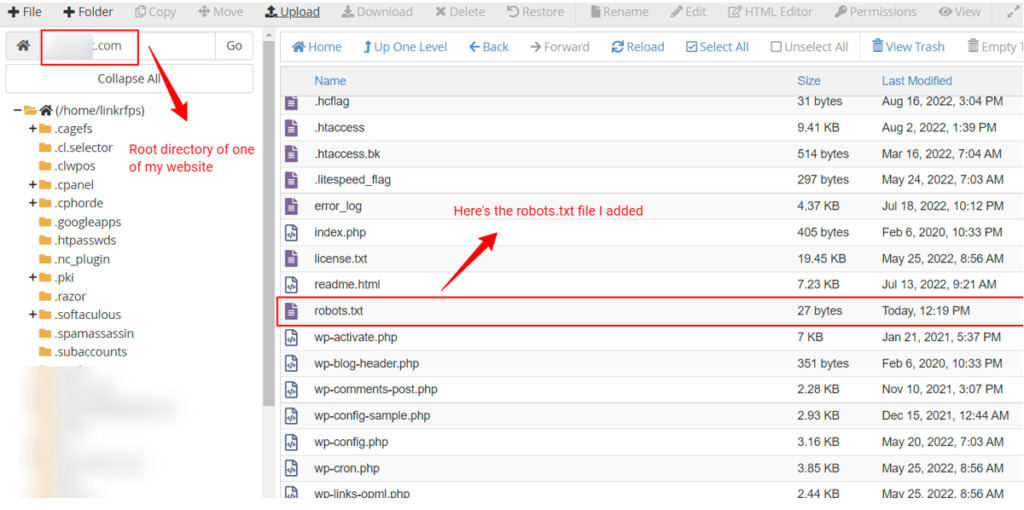
Ensure that you exclude the domains that you want to be crawled.
Pro tip: You must create a robots.txt file for each subdomain you want to block from search engines. Google crawlers will look for the robots.txt file in each of the subdomains.
FAQs
1. How Do I Block a Domain With robots.txt
If you want to block a domain with robots.txt use this code:
User-agent: *
Disallow: /With this code, you can block the entire site.
2. What Should You Block in the robots.txt File
Are you wondering what should be disallowed in robots.txt?
You can block unimportant style files, images, or scripts in the robots.txt file. You can also block URLs in robots txt to prevent Google from indexing expired special offers, private photos, or other pages that are not ready for users to access.
3. What Does Block by Robots.txt Mean?
Blocked by robots.txt means you have certain pages on your site that Google indexed but can’t crawl. Google can view these pages, but it won’t show them as part of search engine results pages.
4. How Do I Remove the Subdomain From the Main Domain?
- Log in to your web hosting account & goto cpanel
- Then go to: Domains
- In front of the sub-domain you want to remove, Click: Manage
- Then, review what is there on the page, if you are sure you want to remove the sub-domain click: Remove
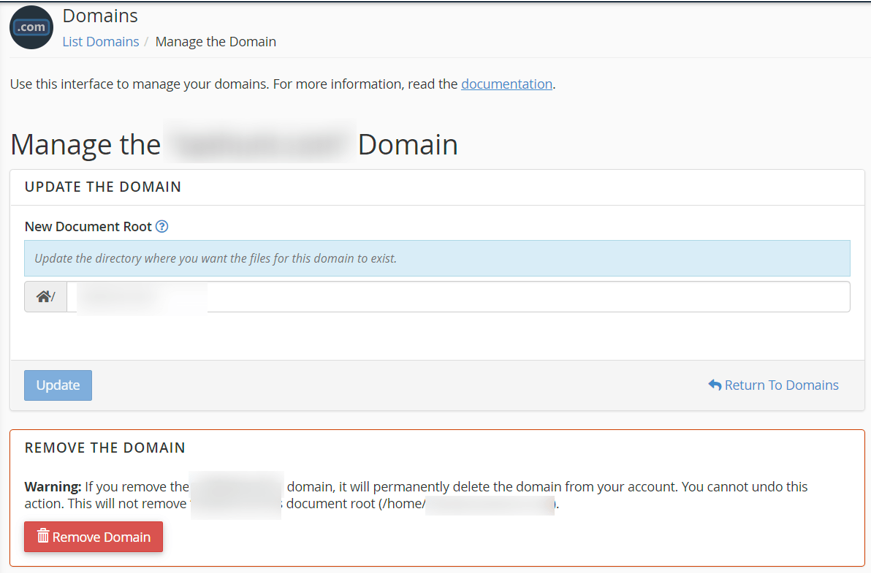
Note: The process & screenshot I have shared from Namecheap hosting. If your website is hosted with a different host the steps could vary.
What Is Disallow in robots.txt?
Disallow in robots.txt tells search engine crawlers not to access the page or set of webpages that come after the command.
Let’s take an example-
File Exclusion:
User-agent: *
Disallow: /test.htmlHere disallow directs the search engine crawlers not to crawl the page named ‘test.html’.
Robots.txt to Disallow Multilevel Subdomains
It won’t be possible to disallow multilevel subdomains by writing Robots.txt for any subdomain or root domain. You will need a robot.txt file for every subdomain you want to block from search engines. You must write separate Robots.txt files to disallow a subdomain.
Final Thoughts on Blocking Subdomain in robots.txt
So now you know how to block a subdomain in robots.txt and how to prevent search engine crawlers from indexing your subdomains.
But if you’re going to edit your robots.txt file, be careful because even a small mistake can lead to disastrous consequences.
For example, if you misplace a single forward slash, it can block the whole directory. Disallowing all robots on a live website can result in a loss of revenue and traffic, and your site can even be removed from search engines.





